

Dự án của mình vừa kết thúc. Vậy là có 3-4 tuần rảnh rang hơn một chút. Mình dùng quãng thời gian này để đọc, và tham gia training cái này cái kia.
GenAI, kể từ lúc ChatGPT xuất hiện, đã thành cơn sốt mới. Cũng dễ hiểu, vì có lẽ đó là cột mốc hữu hình nhất mà con người chúng ta được tương tác với công nghệ, với Trí Tuệ Nhân Tạo trước đó nghe còn cao siêu và xa vời. Bằng cách, có một giao diện, chúng ta có thể cho vào đó mọi câu hỏi trên đời, và ChatGPT sẽ trả lời - dù chỉ là tổng hợp từ các kết quả tìm kiếm phổ biến trên Internet, nhưng câu cú mượt mà nói năng dễ nghe, khác xa các chatbot cà rật cà rật mà ta từng tiếp xúc.
Còn, mình thì... thật ra, không quan tâm đến GenAI mấy. Nhưng, nếu bạn nhiều lần nghe tới và tự hỏi: GenAI là cái gì? Thì, mình cũng vậy đó.
Tóm lại, GenAI nằm ngoài comfort zone của mình.
Hồi mình còn đi học, cơ bản là không có khoá master, cử nhân nào có một chương trình đào tạo riêng về Data Science hay Trí tuệ nhân tạo (AI) cả. Nếu có, các chủ đề này nằm dưới module nhỏ hơn của ngành lớn là Khoa học máy tính. Những đồng nghiệp Data Scientist của mình cũng có nhiều xuất thân, hoặc là học Khoa học máy tính, học các môn nặng định lượng và mô hình toán như là toán học, hoá học, vật lý, cho đến học Kinh doanh - Marketing, chuỗi cung ứng. Mình học Kinh tế lượng, đại khái là mô hình hoá và phương pháp định lượng trong kinh tế.
Data scientist có thể đến từ bất kỳ ngành nào có dùng đến định lượng và mô hình toán. Việc xuất thân từ các ngành khác nhau, cho họ những lợi thế và bất lợi khác nhau. Càng đi xa thì xuất phát điểm càng trở nên ít quan trọng.
Dù vậy, không phải cứ data scientist nào cũng làm về GenAI. Bản thân trong ngành cũng có nhiều sự phân hoá.
AI, machine learning và GenAi liên quan gì đến nhau?
Mình tạm vẽ ra hình minh hoạ như dưới: AI là phạm trù rộng, bao hàm cả Gen AI và Machine learning.
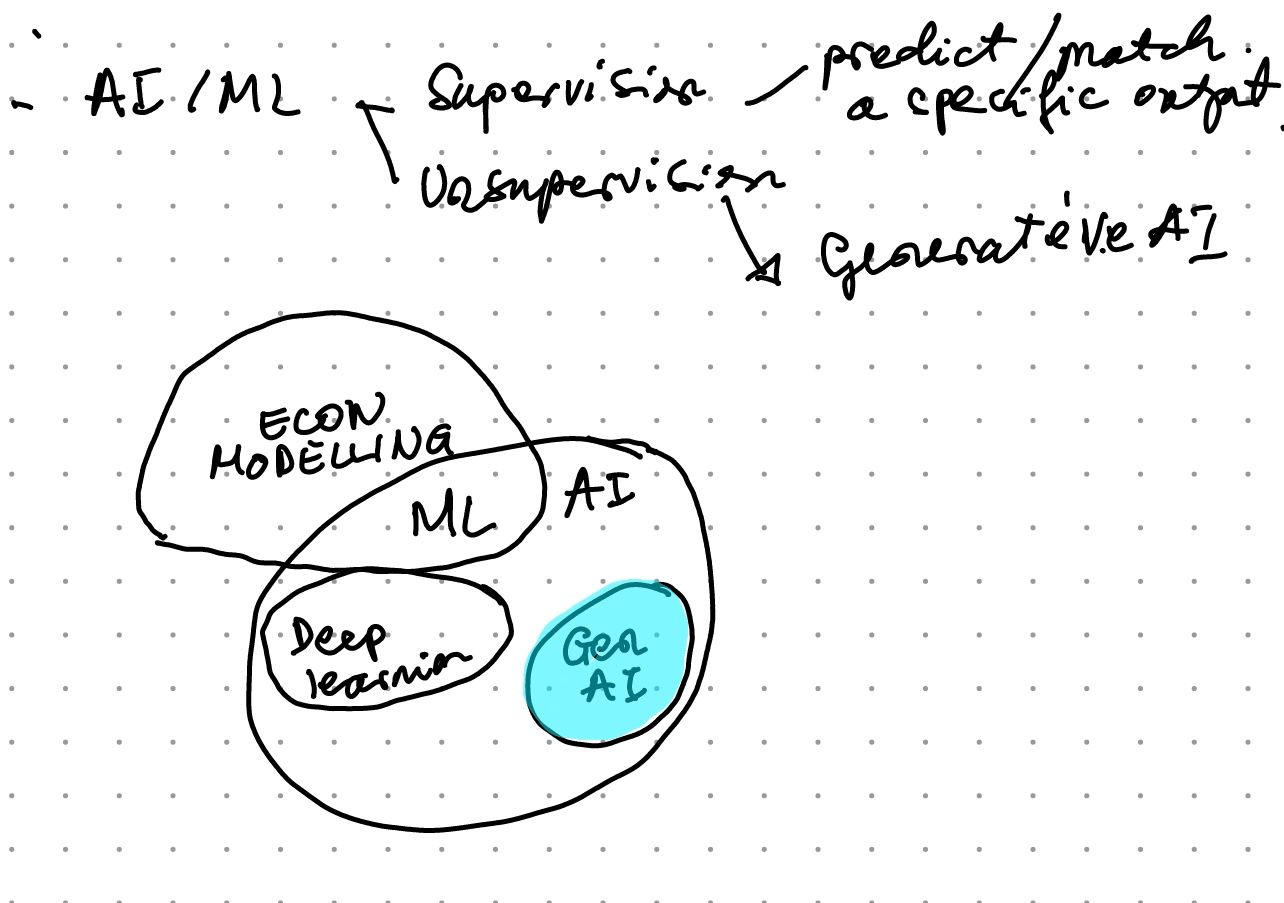
Machine learning (ML) sử dụng dữ liệu để học các quy luật lặp lại về mối liên kết giữa dữ liệu quan sát với một kết quả mục tiêu, từ đó dự đoán một kết quả cụ thể. Ví dụ, dùng dữ liệu về thói quen tiêu dùng, thu nhập, trình độ giáo dục để dự đoán mức rủi ro khi cho vay tín dụng. Hay là, dựa vào các pixels, đường nét trên một bức ảnh để “dự đoán” bức ảnh chụp con chó hay con mèo - từ “dự đoán” ở đâu để trong ngoặt kép, vì “dự đoán” không nhất thiết là nhìn vào điều gì sẽ xảy ra trong tương lai, dự đoán để chỉ những kết quả sẽ/đã biết nhưng tạm thời bị ẩn trong bộ dữ liệu quan sát máy và mô hình xử lý.
Ví dụ về nhận diện ảnh, lại thuộc về nhóm Deep learning (tập con của ML). Nói một cách đơn giản, ở ví dụ về cho vay tín dụng, một mô hình có thể xử lý tầm vài trăm đến dưới 1,000 biến quan sát (yếu tố input dùng để tiên đoán kết quả mục tiêu). Nhưng trong ví dụ hình ảnh, mỗi pixel (yếu tố inputs) có thể là một biến, trong 1 tấm ảnh 1080p có thể có đến 2 triệu pixels. Điều này đòi hỏi các phương pháp học “sâu” hơn, để kết hợp và cả loại bỏ bớt biến inputs.
Kinh tế học cũng có các kỹ thuật mô hình và dự đoán, nhưng đa số các bàn toán gần giống với dạng của bài toán vay tín dụng hơn, với số biến quan sát thường thấp (dưới 1,000 biến). Vì thế, có vùng giao giữa Kinh tế và AI, cụ thể là ở nhóm các mô hình Machine Learning (không phải Deep learning). Dĩ nhiên, các vòng tròn và vùng giao nhau mỗi ngày một nới rộng, khi sự “mượn” kiến thức và kỹ thuật liên ngành ngày càng phổ biến.
GenAI không dự đoán mà tạo ra kết quả
GenAI, cũng sử dụng dữ liệu, nhưng không tồn tại một kết quả mục tiêu cụ thể nào để mô hình dự đoán. GenAI không dự đoán mà tạo ra kết quả, là một đoạn text mới, một bức ảnh mới, một đoạn video - kết hợp từ nhiều đoạn text, hình ảnh và video khác. Một vài ví dụ của GenAI như: Từ nhiều văn bản tổng hợp thành tóm tắt trong 300 từ, hoặc tóm tắt theo các câu hỏi cụ thể (prompt) từ người dùng. GenAI tạo ra những kết quả mới, có thể khiến người ta bất ngờ hoặc thất vọng. Có nhiều cách để đo đạt tính hiệu quả, nhưng khác với ML, sẽ không có một “sự thật” mục tiêu để đo đạt tính chính xác.
Xin nhắc lại, GenAI và mình không có liên quan gì với nhau, và mình còn thơ ơ với nó hơn nhiều người yêu mến công nghệ khác. Với mình GenAI là một trào lưu sớm nở thì sớm tàn.
Nhiều khi cái hay của FOMO là nó buộc người ta phải bương mình ra thử những cái mà nếu không FOMO họ sẽ chẳng bao giờ ngó ngàng tới.
Dù không quan tâm, nhưng vì FOMO mình đã tham gia 1 cái training về GenAI.
Cái training mà mình tham gia, hẳn là muốn thử thách lòng người. Lại diễn ra từ lúc 11 giờ đêm, đến 7 giờ sáng. Mình đã hứng thú và thấy hay ho hơn mức mình tưởng.
Mình note lại bên dưới một vài điểm hay ho, mà một người không-biết-gì-về-GenAI đã thu nhặt được:
- Khác với các mô hình ML (dưới 1,000 biến) mà tự thân các doanh nghiệp có thể tự xây dựng bằng dữ liệu nội bộ, GenAI là những mô hình siêu lớn, ngốn cực nhiều cơ sở vật chất và cả dữ liệu tích luỹ để xây dựng. Về cơn bản, nếu GenAI được ứng dụng trong doanh nghiệp, doanh nghiệp đó sẽ không tự xây, mà dùng các mô hình được xây dựng sẵn của các ông lớn như Google, Amazon, Microsoft, OpenAI.
- Phần lớn các mô hình GenAI hiện tại có thể hoạt động ở enterprise-level và đủ tốt để phục vụ thương mại thường không phải là nguồn mở, tức là chúng ta không thể download mô hình về và mổ xẻ xem bên trong có gì. Các GenAI provider (OpenAI, Google, Microsoft) sẽ cung cấp 1 API (tưởng tượng nó giống như 1 dạng SMS dưới ngôn ngữ lập trình), để gắn vào apps và kết nối với mô hình của họ. Ví dụ, nếu bạn tương tác với chatbot GPT - dù là được cài trên máy bạn, thì các tin nhắn của bạn sẽ được gửi qua API tới mô hình của OpenAI để xử lý và trả lại thông tin, vì thế nếu không có kết nối mạng thì chatbot này không hoạt động trên máy tính của bạn.
- Dù sử dụng một mô hình GenAI có sẵn (như điều 1), bạn vẫn có thể tuỳ chỉnh bằng nhiều cách. Cung cấp thêm các tài liệu dưới dạng Context cho mô hình, điều chỉnh các chỉ số để thay đổi độ dài câu trả lời, hình thức trả lời (đoạn văn hay gạch đầu dòng), tính sáng tạo (trả lời ngắn gọn và đảm bảo vào trọng tâm, hay có chút dông dài nhưng biết đâu ngẫu nhiên có thêm vài thông tin thú vị)
- Cách giao tiếp qua API (như điều 2), có thể làm nảy sinh những lo ngại về bảo mật thông tin.
- Vì cả (1) và (2), đôi khi việc ứng dụng GenAI cho một doanh nghiệp là câu chuyện của kỹ sư (Data/ML/AI engineer, app engineer) nhiều hơn là của data scientist
- GenAI có thể ứng dụng cho cả ngôn ngữ, hình ảnh/video, âm thanh. Riêng về ngôn ngữ, ứng dụng GenAI cho các ngôn ngữ hiếm (như tiếng Việt, tiếng Lào, tiếng Thái) còn nhiều hạn chế
- Cuối cùng, và là điều mình tâm đắc nhất, GenAI không phải phép thần thông, nó là một công cụ để tự động hoá một số bước trong công việc của con người: Như là tóm tắt tài liệu (khi có quá nhiều hình ảnh), mô tả hình ảnh (khi có quá nhiều tấm ảnh). GenAI cho phép chúng ta xử lý một lượng lớn thông tin, thu gọn phạm vi lại, rồi từ đó bản thân con người phải xử lý tiếp. Hoặc tạo ra một nội dung mới, mà con người vẫn cần xem xét và đánh giá điều chỉnh thêm (Hãy nhớ là GenAI không dự đoán, mà tạo ra kết quả. Ta không có một sự thật cụ thể để đánh giá một cách hệ thống tính chính xác của nó).
Nên nếu ai hỏi rằng, GenAI có thay thế con người không, thì mình dám nói là không, nhưng GenAI thay đổi con người, ở cách chúng ta làm việc. Hệ luỵ của các phát minh thường là đến ở cách con người sử dụng chúng, nếu chúng ta ỷ lại vào công nghệ, dĩ nhiên ta sẽ hứng chịu tác dụng phụ.
Bonus thêm cho bạn nào có quan tâm về pipeline ứng dụng GenAI.
Bên dưới là ghi chép về một ví dụ ứng dụng GenAI để tổng hợp 1,000 file PDF tài liệu về chính sách sản phẩm của công ty thành một đoạn tóm tắt 500 chữ.
- (1) File PDF được xử lý bằng Document AI (API) dùng công nghệ OCR để chuyển thành file text, các files tài liệu này sẽ được dùng như Context để tuỳ chỉnh mô hình GenAI xây dựng sẵn
- (2) Vì GenAI model gọi bằng API giới hạn số ký tự (token), 1000 files PDF có thể có đến cả triệu ký tự sẽ không thể gửi trong 1 lần call API được. Chúng ta có thể sử dụng chiến lược “Chia để trị” (MR - Map Reduce) để xử lý:
- -- (i) Chia nhỏ text từ 1000 files thành các đoạn nhỏ (chunk) với kích cỡ có thể xử lý được, ví dụ chia thành 100 chunks
- -- (ii) Mỗi chunk được gửi bằng API (Map), để GenAI tóm tắt chunk đó. Vì là tóm tắt, nên API sẽ trả lại kết quả là 100 đoạn tóm tắt có kích thước ngắn hơn sơ với chunk được gửi đi (Reduce)
- -- (iii) Ta lại gom các 100 đoạn tóm tắt để gửi thêm một lần nữa, và tóm tắt lại 100 đoạn tóm tắt. Kết quả cuối cùng là đoạn tóm tắt nội dung của 1000 files PDF
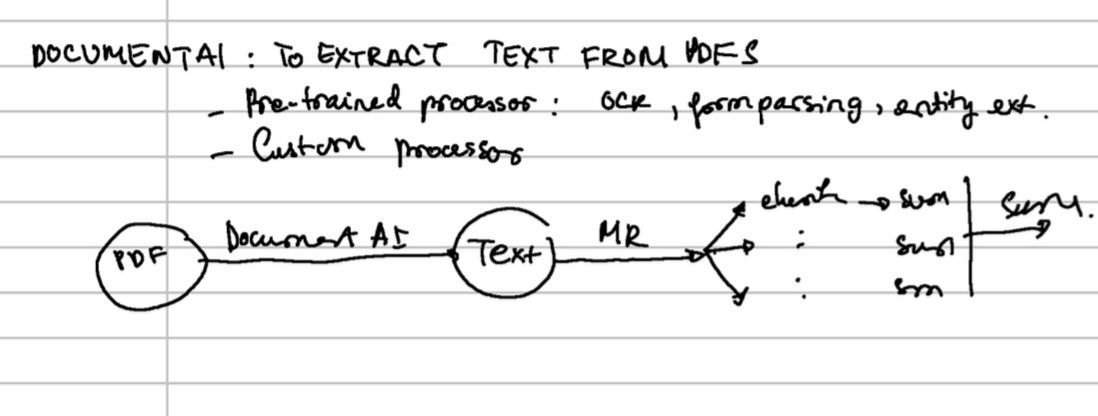
Sẽ có nhiều phương pháp MapReduce với ưu nhược điểm khác nhau, nhưng đây là cách đơn giản nhất. Cách tiếp cận chia-để-trị này không chỉ dùng trong GenAI, mà còn dung trong rất nhiều bài toán xử lý dữ liệu lớn khác.

